Convert Existing Biomarker Data Into Revenue Capacity
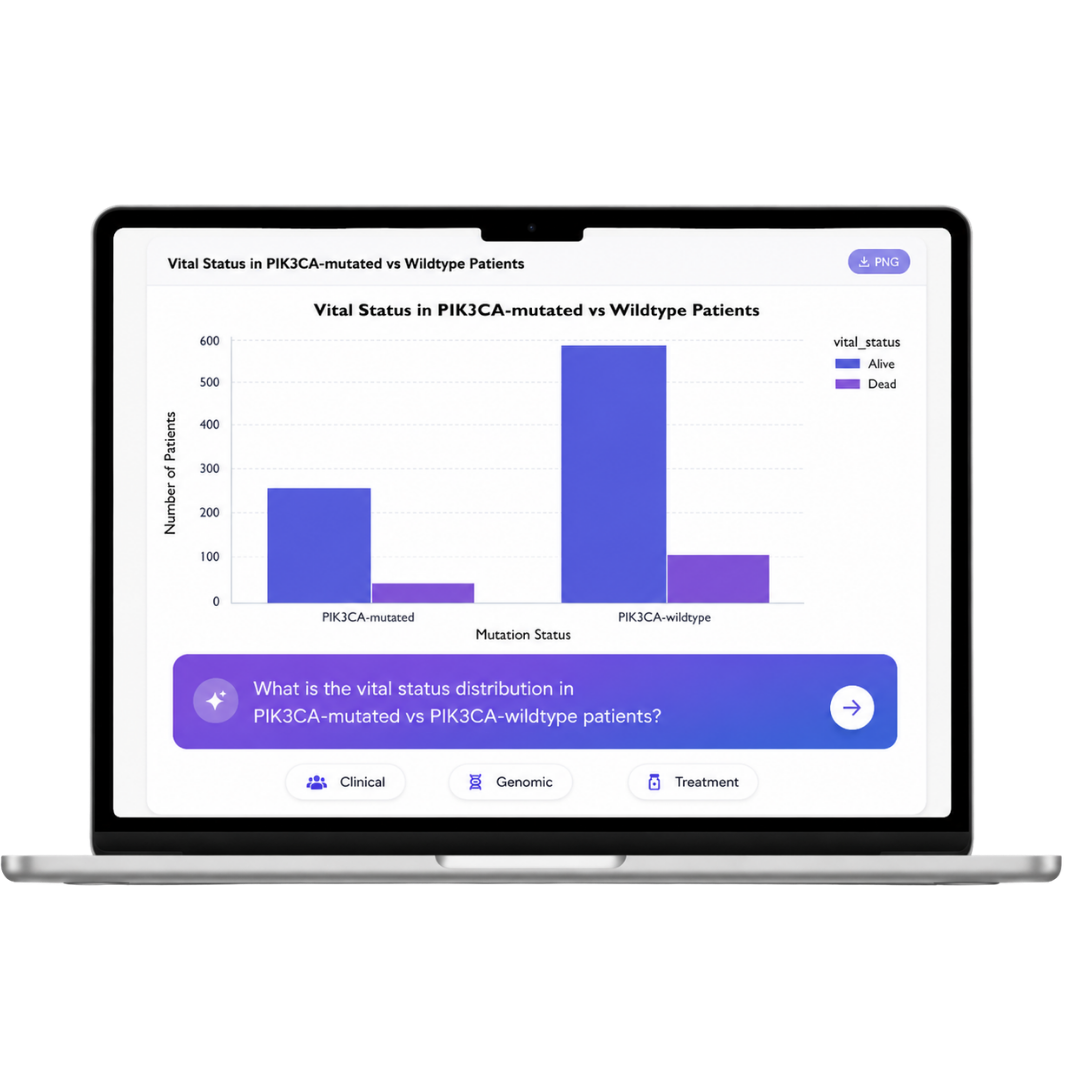
OmicsLayer™ turns disorganized multimodal biomarker data into reusable pharma-ready workflows for cohort selection, responder prediction, patient analysis, and evidence packages.
10–25% improvement in cohort-screening efficiency with lower sponsor-review friction
- Standardize how cohorts, biomarkers, and supporting evidence are prepared for sponsor-facing review
- Reduce back-and-forth during pharma and FDA-facing discussions
- Minimize rework caused by missing provenance, inconsistent outputs, or manually assembled evidence
- Improve audit-readiness with traceable queries, reusable evidence templates, and structured outputs
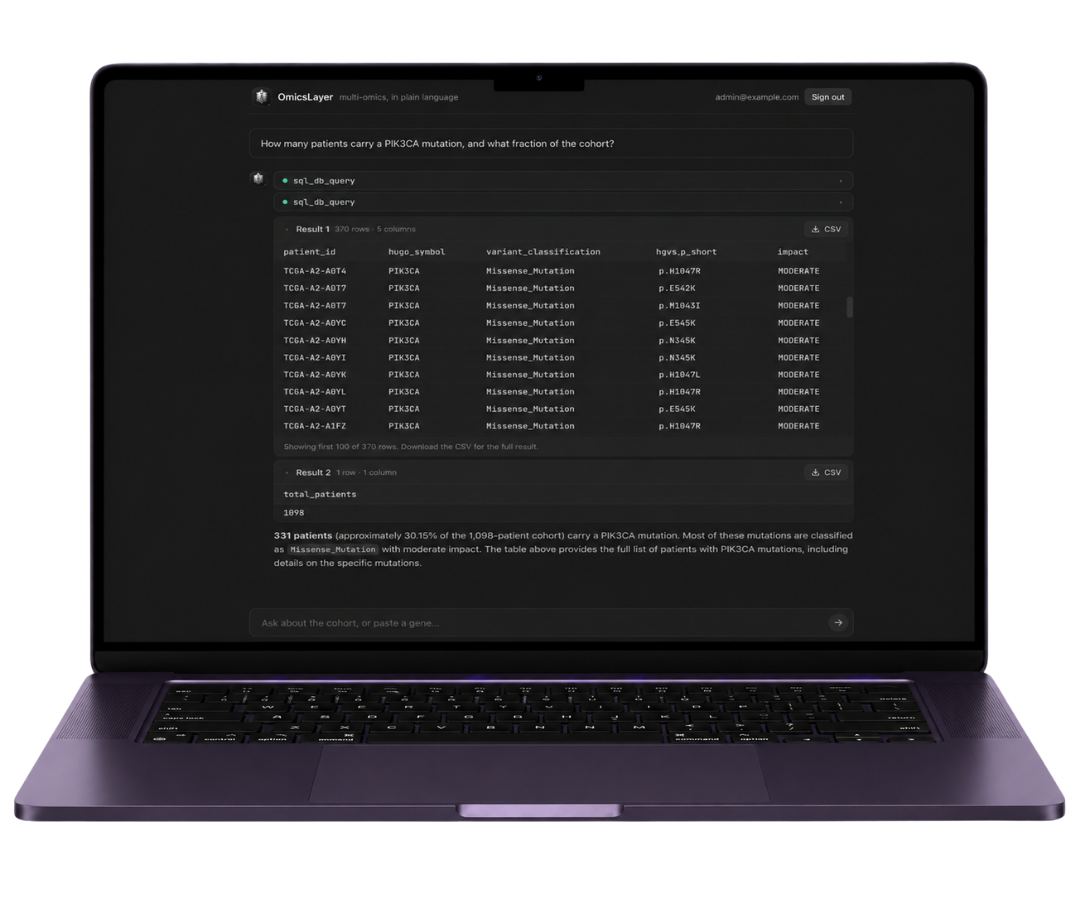
EUR 40k–120k/year in higher project margin from reduced manual scientific prep
- Cut repeated manual work across data science and modality teams
- Reuse saved queries, exports, metadata links, and evidence templates across projects
- Reduce time spent on reassembling the same sponsor-facing materials for each request
- Typical savings are based on avoided internal effort at a fully loaded scientific/data team cost
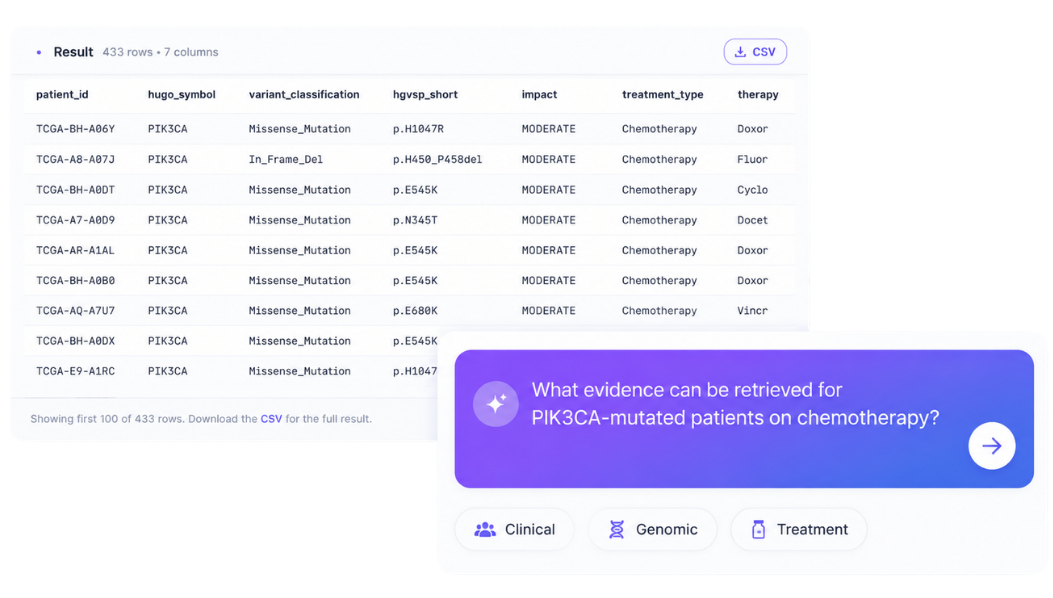
40–70% faster sponsor response turnaround
- Answer feasibility questions using searchable cohorts, biomarkers, files, analysis outputs, and provenance
- Replace manual data assembly with structured, reusable evidence retrieval
- Shorten response cycles for sponsor requests, cohort questions, and evidence follow-ups
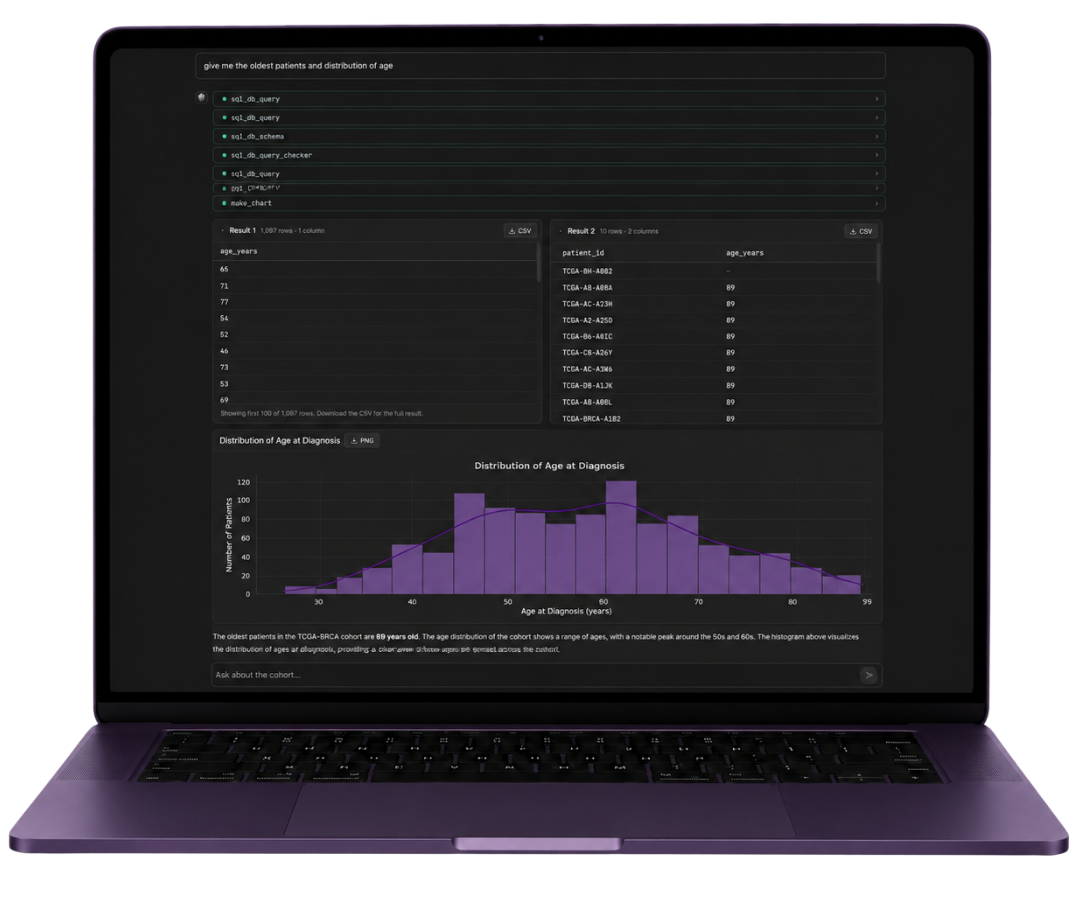
+EUR 150k–500k/year in additional pharma-partner revenue
- Sell higher-value work packages instead of one-off analysis requests
- Package biomarker analysis, cohort selection, trial feasibility evidence, and responder/non-responder stratification into sponsor-ready offerings
- Expand existing partner accounts with additional evidence-generation services
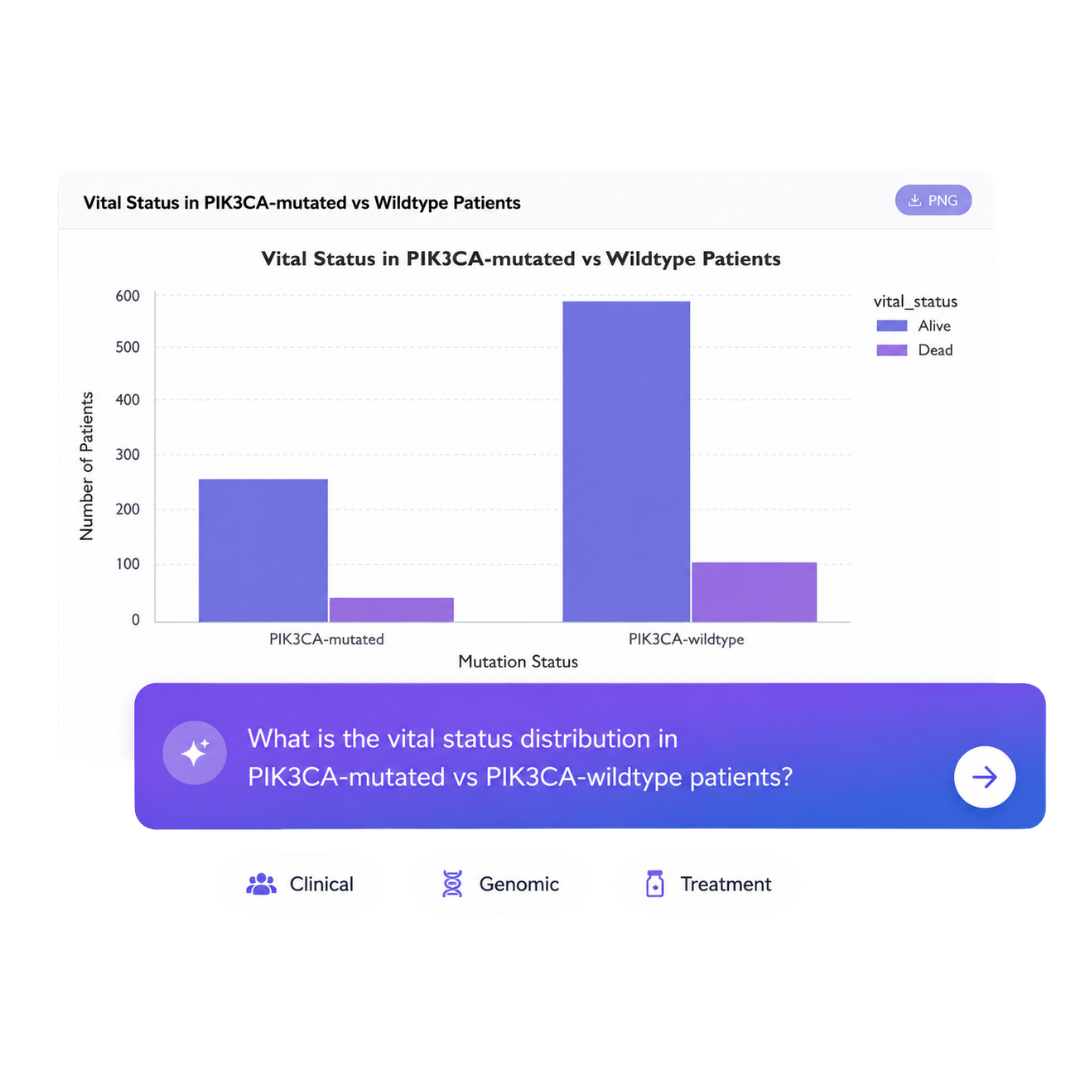
Based on our clients’ experience, OmicsLayer™ saves around €40k–120k/year in avoided manual internal resources.




Trusted by Industry Leaders:
Start with a free demo on your own data
See how the solution works in practice before committing to deployment or integration.
Secure on-prem/private cloud installation process
Discovery & data audit
-
1–2 weeks
Workshops with scientific, data, IT, and compliance teams. We define systems, datasets, permissions, and the first high-value use case.
Data & architecture mapping
-
2–3 weeks
We map data flows, metadata, access logic, pipeline dependencies, and integration points.
Build & integration
-
4–8 weeks
We connect priority systems, build ingestion/QC workflows, configure the semantic layer, and prepare the AI query interface.
Pilot validation
-
2–4 weeks
We test the first use case on real data, validate answer quality, review traceability, and tune workflows with domain experts
Scale & optimization
-
Ongoing
Add new systems, cohorts, data modalities, dashboards, partner workspaces, and additional AI-assisted workflows.
Built for companies where biomedical data already exists
Get in touch with us.
We’re here to assist you.


